

gpOptimizer: Single-Task Acquisition Functions#
#!pip install gpcam==8.4.0
#!pip install matplotlib
Setup#
import numpy as np
import matplotlib.pyplot as plt
from gpcam import GPOptimizer
import time
from loguru import logger
from distributed import Client
client = Client()
%load_ext autoreload
%autoreload 2
from itertools import product
x_pred1D = np.linspace(0,1,1000).reshape(-1,1)
Data Preparation#
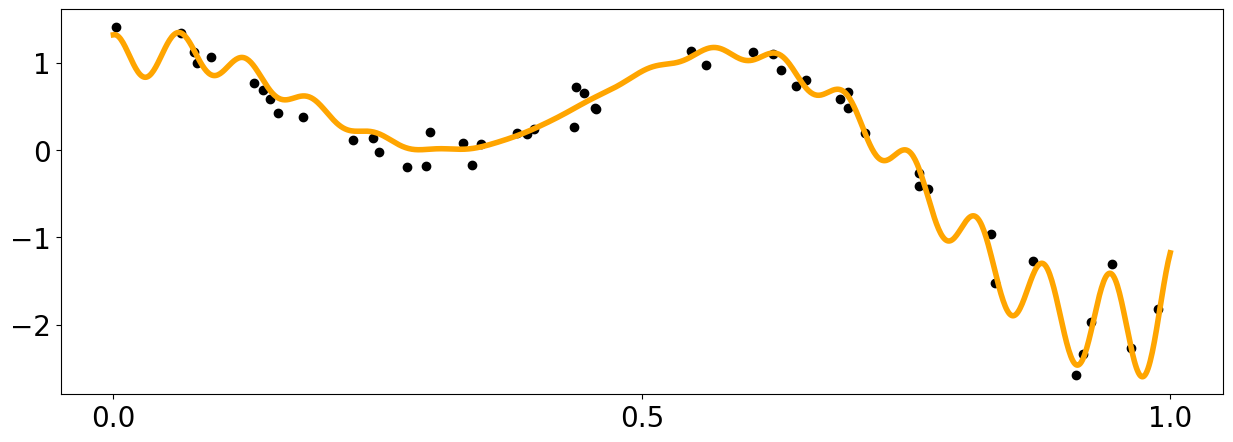
x = np.linspace(0,600,1000)
def f1(x):
return np.sin(5. * x) + np.cos(10. * x) + (2.* (x-0.4)**2) * np.cos(100. * x)
x_data = np.random.rand(50).reshape(-1,1)
y_data = f1(x_data[:,0]) + (np.random.rand(len(x_data))-0.5) * 0.5
plt.figure(figsize = (15,5))
plt.xticks([0.,0.5,1.0])
plt.yticks([-2,-1,0.,1])
plt.xticks(fontsize=20)
plt.yticks(fontsize=20)
plt.plot(x_pred1D,f1(x_pred1D), color = 'orange', linewidth = 4)
plt.scatter(x_data[:,0],y_data, color = 'black')
<matplotlib.collections.PathCollection at 0x7f329c192090>
Customizing the Gaussian Process#
def my_noise(x,hps):
#This is a simple noise function but can be made arbitrarily complex using many hyperparameters.
#The noise function can return a matrix or a vector
return np.zeros((len(x))) + hps[2]
#stationary
from gpcam.kernels import *
def skernel(x1,x2,hps):
#The kernel follows the mathematical definition of a kernel. This
#means there is no limit to the variety of kernels you can define.
d = get_distance_matrix(x1,x2)
return hps[0] * matern_kernel_diff1(d,hps[1])
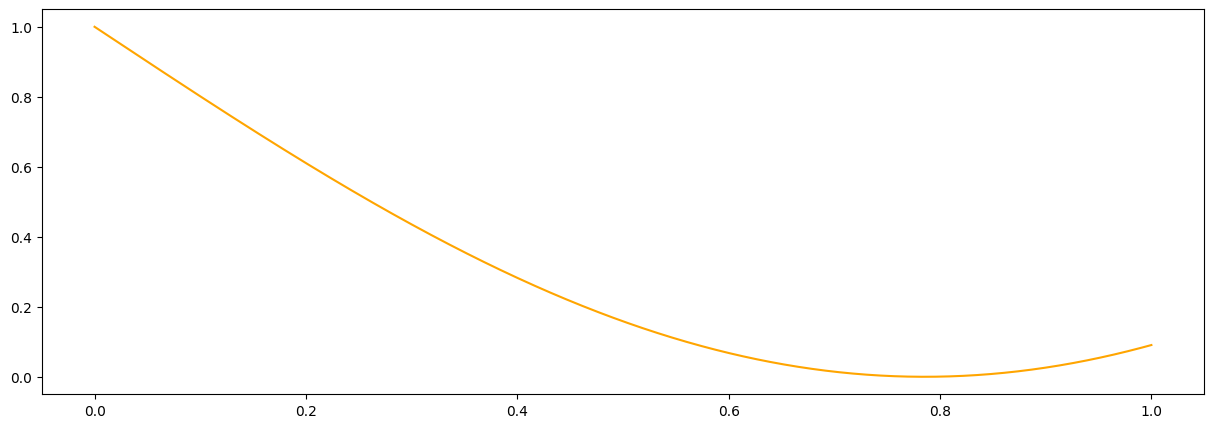
def meanf(x, hps):
#This is a simple mean function but it can be arbitrarily complex using many hyperparameters.
return 1.-np.sin(hps[3] * x[:,0])
#it is a good idea to plot the prior mean function to make sure we did not mess up
plt.figure(figsize = (15,5))
plt.plot(x_pred1D,meanf(x_pred1D, np.array([1.,1.,5.0,2.])), color = 'orange', label = 'task1')
[<matplotlib.lines.Line2D at 0x7f327d613e90>]
Initialization and Different Training Options#
my_gpo = GPOptimizer(x_data,y_data,
init_hyperparameters = np.ones((4))/10., # We need enough of those for kernel, noise, and prior mean functions
compute_device='cpu',
kernel_function=skernel,
kernel_function_grad=None,
prior_mean_function=meanf,
prior_mean_function_grad=None,
noise_function=my_noise,
#noise_variances=np.zeros(y_data.shape) + 0.1,
gp2Scale = False,
ram_economy=False,
args={'a': 1.5, 'b':2.},
)
hps_bounds = np.array([[0.01,10.], #signal variance for the kernel
[0.01,10.], #length scale for the kernel
[0.00001,0.1], #noise
[0.00001,1.] #mean
])
#the following is not needed, this is just to show how data is replced or appended
x_update = np.array([0.1,0.2,0.5]).reshape(3,1)
y_update = f1(x_update[:,0]) + (np.random.rand(len(x_update))-0.5) * 0.5
my_gpo.tell(x_update, y_update, append=True) ##append to the data
my_gpo.tell(x_data, y_data, append=False) ## back to normal overwriting the updated data
st = time.time()
print("Standard Training (MCMC)")
hps = my_gpo.train(hyperparameter_bounds=hps_bounds, info = True, max_iter = 100)
print("Result=", hps, "after ", time.time() - st, " seconds")
print("")
print("ADAM")
hps = my_gpo.train(hyperparameter_bounds=hps_bounds, info = True, max_iter = 100, method="adam")
print("Result=", hps, "after ", time.time() - st, " seconds")
print("")
print("Global Training")
my_gpo.train(hyperparameter_bounds=hps_bounds, method='global', max_iter = 20)
print("Result=", hps, "after ", time.time() - st, " seconds")
print("")
print("Local Training")
my_gpo.train(hyperparameter_bounds=hps_bounds, method='local')
print("Result=", hps, "after ", time.time() - st, " seconds")
print("")
print("HGDL Training")
my_gpo.train(hyperparameter_bounds=hps_bounds, method='hgdl', max_iter=2, dask_client=client)
print("Result=", hps, "after ", time.time() - st, " seconds")
print("")
Standard Training (MCMC)
Starting likelihood. f(x)= -57.45359939750017
Finished 10 out of 100 iterations. f(x)= -57.45359939750017
Finished 20 out of 100 iterations. f(x)= -57.45359939750017
Finished 30 out of 100 iterations. f(x)= -22.700249071580544
Finished 40 out of 100 iterations. f(x)= -18.638280971306042
Finished 50 out of 100 iterations. f(x)= -19.052535503071805
Finished 60 out of 100 iterations. f(x)= -16.64788686268859
Finished 70 out of 100 iterations. f(x)= -16.66045939452155
Finished 80 out of 100 iterations. f(x)= -15.16518351381081
Finished 90 out of 100 iterations. f(x)= -15.414557536356075
Result= [1.68898969 0.36754555 0.07665019 0.02754226] after 0.04072451591491699 seconds
ADAM
Result= [1.99519374 0.38528064 0.04630458 0.86115948] after 0.13742733001708984 seconds
Global Training
Result= [1.99519374 0.38528064 0.04630458 0.86115948] after 0.4720752239227295 seconds
Local Training
Result= [1.99519374 0.38528064 0.04630458 0.86115948] after 0.47588443756103516 seconds
HGDL Training
Result= [1.99519374 0.38528064 0.04630458 0.86115948] after 1.300339937210083 seconds
Asynchronous Training#
Train asynchronously – via Adam, HGDL, or MCMC – on a remote server or locally. You can also start a bunch of different training runs on different computers. This training will continue without any signs of life until you query the solution via ‘update_hyperparameters(object)’ or call ‘my_gpo.stop_training(opt_obj)’
HGDL#
my_gpo.set_hyperparameters(np.ones((4))/10.)
opt_obj = my_gpo.train(hyperparameter_bounds=hps_bounds, dask_client=client, asynchronous=True, method="hgdl")
print(my_gpo.hyperparameters)
for i in range(20):
my_gpo.update_hyperparameters(opt_obj)
print("iteration ", i, " : ",my_gpo.hyperparameters)
time.sleep(0.1)
my_gpo.stop_training(opt_obj) ##this leaves the dask client alive, kill_client() will shut it down.
[0.1 0.1 0.1 0.1]
iteration 0 : [0.1 0.1 0.1 0.1]
iteration 1 : [1.58964583 0.35133771 0.0463426 1. ]
/home/marcus/Coding/fvGP/fvgp/gp.py:881: UserWarning: Hyperparameter update not successful len(optima list) = 0
hps = self.trainer.update_hyperparameters(opt_obj)
iteration 2 : [1.58964583 0.35133771 0.0463426 1. ]
iteration 3 : [1.58964583 0.35133771 0.0463426 1. ]
iteration 4 : [1.58964583 0.35133771 0.0463426 1. ]
iteration 5 : [1.58964583 0.35133771 0.0463426 1. ]
iteration 6 : [1.58964583 0.35133771 0.0463426 1. ]
iteration 7 : [1.58964583 0.35133771 0.0463426 1. ]
iteration 8 : [1.58964583 0.35133771 0.0463426 1. ]
iteration 9 : [1.58964583 0.35133771 0.0463426 1. ]
iteration 10 : [1.58964583 0.35133771 0.0463426 1. ]
iteration 11 : [1.58964583 0.35133771 0.0463426 1. ]
iteration 12 : [1.58964583 0.35133771 0.0463426 1. ]
iteration 13 : [1.58964583 0.35133771 0.0463426 1. ]
iteration 14 : [1.58964583 0.35133771 0.0463426 1. ]
iteration 15 : [1.58964583 0.35133771 0.0463426 1. ]
iteration 16 : [1.58964583 0.35133771 0.0463426 1. ]
iteration 17 : [1.58964583 0.35133771 0.0463426 1. ]
iteration 18 : [1.58964583 0.35133771 0.0463426 1. ]
iteration 19 : [1.58964583 0.35133771 0.0463426 1. ]
ADAM#
my_gpo.set_hyperparameters(np.array([1.,1.,1.,1.]))
print(my_gpo.hyperparameters)
opt_obj = my_gpo.train(hyperparameter_bounds=hps_bounds, dask_client=client, asynchronous=True, method='adam')
# The result won't change much (or at all) since this is such a simple optimization
for i in range(20):
my_gpo.update_hyperparameters(opt_obj)
print("iteration ", i, " : ",my_gpo.hyperparameters)
time.sleep(0.1)
my_gpo.stop_training(opt_obj) ##this leaves the dask client alive, kill_client() will shut it down.
[1. 1. 1. 1.]
iteration 0 : [8.18982648 9.10473692 0.05892872 0.14106267]
iteration 1 : [8.77385382 8.51139661 0.34629171 0.81652448]
iteration 2 : [9.15980363 8.04148331 0.42356338 0.91935441]
iteration 3 : [9.53612743 7.52049452 0.46979084 0.9178787 ]
iteration 4 : [9.89090397 6.96833202 0.49523519 0.90090135]
iteration 5 : [10.31926567 6.21066282 0.50912542 0.86887424]
iteration 6 : [10.81752773 5.18678682 0.50720787 0.82268905]
iteration 7 : [11.52099983 3.49057575 0.47492533 0.77255324]
iteration 8 : [12.4685126 0.69733624 0.24422075 0.8679103 ]
iteration 9 : [12.20727962 0.77255015 0.0463097 0.97412546]
iteration 10 : [11.90286014 0.76586561 0.04681552 1.07606152]
iteration 11 : [11.56083602 0.75794917 0.04681097 1.17149964]
iteration 12 : [11.18136305 0.74887599 0.04680381 1.25706446]
iteration 13 : [10.77359909 0.73881135 0.0467952 1.3289291 ]
iteration 14 : [10.34198007 0.72782024 0.04678567 1.38642828]
iteration 15 : [9.86324784 0.71522791 0.04677497 1.43259195]
iteration 16 : [9.33667396 0.70087426 0.04676315 1.46727396]
iteration 17 : [8.77404513 0.68491594 0.04675035 1.49101978]
iteration 18 : [8.15384692 0.66650493 0.04673571 1.50640015]
iteration 19 : [7.4745217 0.64522308 0.04671854 1.51490218]
MCMC#
my_gpo.set_hyperparameters(np.array([1.,1.,1.,1.]))
print(my_gpo.hyperparameters)
opt_obj = my_gpo.train(hyperparameter_bounds=hps_bounds, dask_client=client, asynchronous=True, method='mcmc')
# The result won't change much (or at all) since this is such a simple optimization
for i in range(20):
my_gpo.update_hyperparameters(opt_obj)
print("iteration ", i, " : ",my_gpo.hyperparameters)
time.sleep(0.1)
my_gpo.stop_training(opt_obj) ##this leaves the dask client alive, kill_client() will shut it down.
[1. 1. 1. 1.]
iteration 0 : [1. 1. 1. 1.]
iteration 1 : [4.29020852 0.52215149 0.04951336 0.84548404]
iteration 2 : [3.87184689 0.38126789 0.04917364 0.79921262]
iteration 3 : [4.20315227 0.61810961 0.05407959 0.79052919]
iteration 4 : [5.04179296 0.61164863 0.04101402 0.51311478]
iteration 5 : [6.64855494 0.63610798 0.03659832 0.07039344]
iteration 6 : [5.92080706 0.56959858 0.04098325 0.14807541]
iteration 7 : [3.98004501 0.52633057 0.03790581 0.81188697]
iteration 8 : [5.15165494 0.46787565 0.04043386 0.58640984]
iteration 9 : [4.52853608 0.72597793 0.06039227 0.40916232]
iteration 10 : [2.60594224 0.44943824 0.05409285 0.66368617]
iteration 11 : [7.41323269 0.86061831 0.04976672 0.11716609]
iteration 12 : [4.71188782 0.56203315 0.042081 0.40070252]
iteration 13 : [3.53262614 0.46961484 0.05058613 0.68431976]
iteration 14 : [2.15225919 0.33381461 0.05561555 0.94886426]
iteration 15 : [1.02067381 0.24300803 0.05752397 0.96274661]
iteration 16 : [1.21308594 0.34185284 0.06570075 0.86006406]
iteration 17 : [2.72030551 0.46295341 0.06399514 0.7718477 ]
iteration 18 : [2.14410773 0.36908653 0.08491103 0.47272333]
iteration 19 : [1.49939774 0.33391577 0.07033396 0.60716589]
Vizualizing the Results#
#let's make a prediction
x_pred = np.linspace(0,1,1000)
hps = my_gpo.train(hyperparameter_bounds=hps_bounds, info = False)
# different ways to call
var1 = my_gpo.posterior_covariance(x_pred.reshape(-1,1), variance_only=False, add_noise=False)["v(x)"]
var1 = my_gpo.posterior_covariance(x_pred.reshape(-1,1), variance_only=False, add_noise=True)["v(x)"]
mean1 = my_gpo.posterior_mean(x_pred.reshape(-1,1))["m(x)"]
var1 = my_gpo.posterior_covariance(x_pred.reshape(-1,1), variance_only=False, add_noise=True)["v(x)"]
mean_grad = my_gpo.posterior_mean_grad(x_pred.reshape(-1,1), direction=0)["dm/dx"]
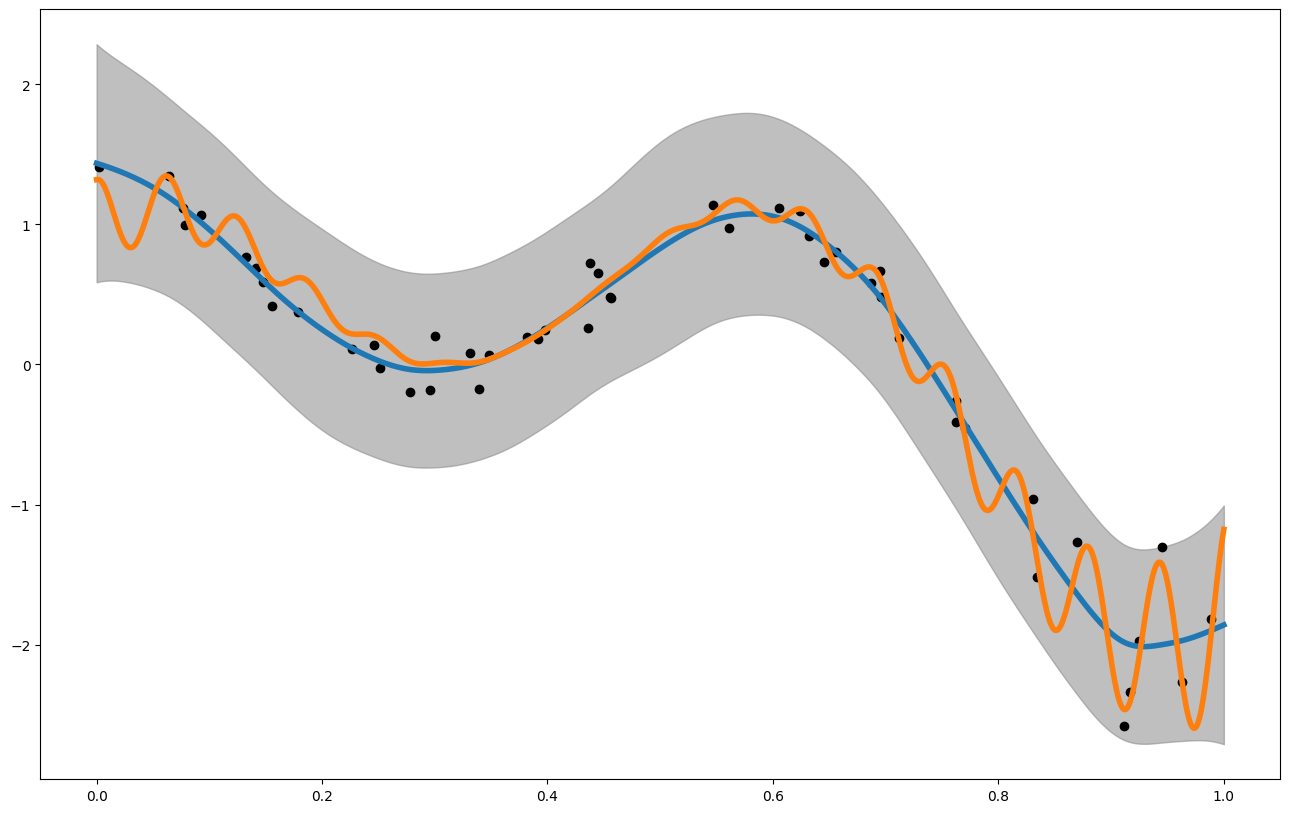
print("Posterior Mean and Uncertainty")
plt.figure(figsize = (16,10))
plt.plot(x_pred,mean1, label = "posterior mean", linewidth = 4)
plt.plot(x_pred1D,f1(x_pred1D), label = "latent function", linewidth = 4)
plt.fill_between(x_pred, mean1 - 3. * np.sqrt(var1), mean1 + 3. * np.sqrt(var1), alpha = 0.5, color = "grey", label = "var")
plt.scatter(my_gpo.x_data,my_gpo.y_data, color = 'black')
plt.show()
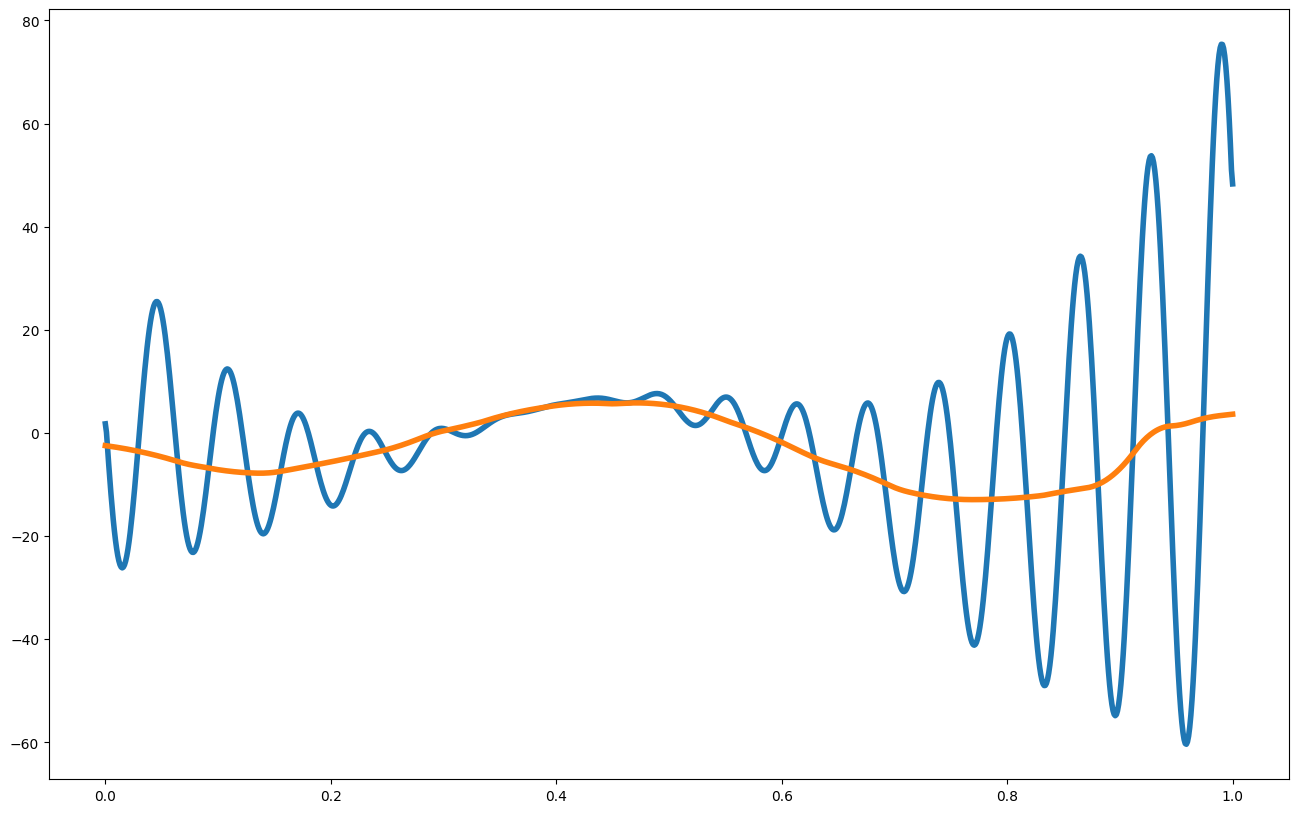
print("Posterior Mean Gradient")
plt.figure(figsize = (16,10))
dx = 1./len(x_pred)
plt.plot(x_pred1D,np.gradient(f1(x_pred1D).flatten(), dx), label = "ground truth gradient", linewidth = 4)
plt.plot(x_pred1D,mean_grad, label = "posterior mean grad", linewidth = 4)
plt.show()
##looking at some validation metrics
print("RMSE: ",my_gpo.rmse(x_pred1D,f1(x_pred1D).flatten()))
print("NRMSE: ",my_gpo.nrmse(x_pred1D,f1(x_pred1D).flatten()))
print("CRPS (mean, std): ",my_gpo.crps(x_pred1D,f1(x_pred1D).flatten()))
print("R2: ",my_gpo.r2(x_pred1D,f1(x_pred1D).flatten()))
print("NLPD: ",my_gpo.nlpd(x_pred1D,f1(x_pred1D).flatten()))
print("MSLL: ",my_gpo.msll(x_pred1D,f1(x_pred1D).flatten()))
print("MAPE: ",my_gpo.mape(x_pred1D,f1(x_pred1D).flatten()))
print("INTERVAL SCORE: ",my_gpo.interval_score(x_pred1D,f1(x_pred1D).flatten()))
print("MPIW: ",my_gpo.mpiw(x_pred1D))
print("PICP: ",my_gpo.picp(x_pred1D,f1(x_pred1D).flatten()))
print("Coverage Curve:")
cov_curve = my_gpo.coverage_curve(x_pred1D,f1(x_pred1D).flatten())
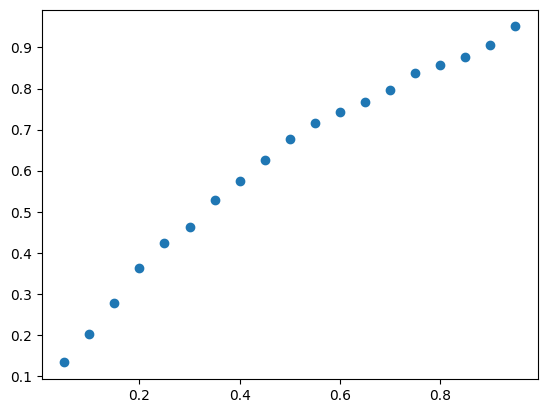
plt.scatter(cov_curve["target_coverage"], cov_curve["measured_coverage"])
plt.show()
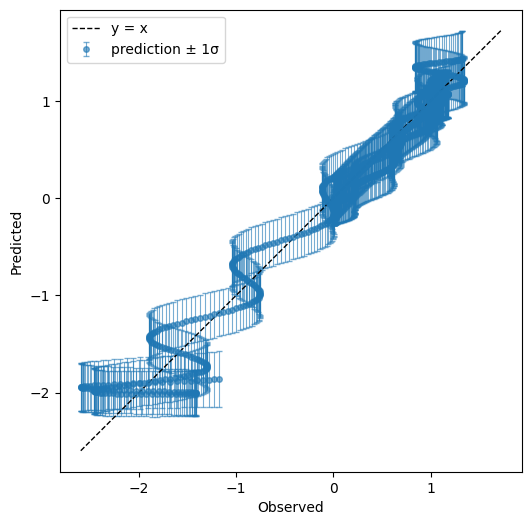
print("predicted vs. observed")
my_gpo.plot_observed_vs_predicted(x_pred1D,f1(x_pred1D).flatten())
Posterior Mean and Uncertainty
Posterior Mean Gradient
RMSE: 0.20773325650420307
NRMSE: 0.05267198239179237
CRPS (mean, std): (np.float64(0.11518355308115732), np.float64(0.12482752059068643))
R2: 0.9594676277137122
NLPD: 0.4367242211316339
MSLL: -1.0148770461937344
MAPE: 1.1468766010435933
INTERVAL SCORE: 1.0647691954820597
MPIW: 0.9303924244781772
PICP: 0.951
Coverage Curve:
predicted vs. observed
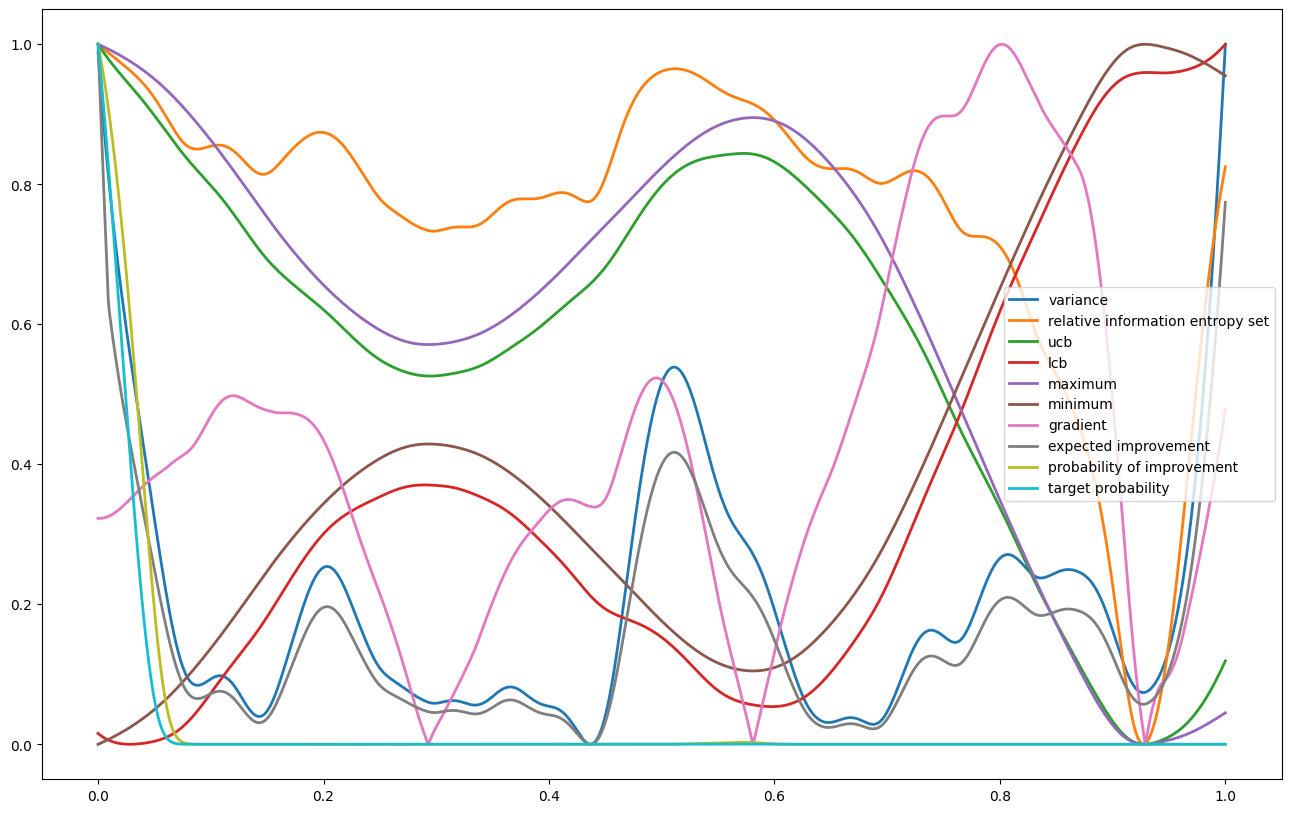
#available acquisition function for the single-task case:
acquisition_functions = ["variance","relative information entropy","relative information entropy set",
"ucb","lcb","maximum","minimum","gradient","expected improvement",
"probability of improvement", "target probability", "total correlation"]
plt.figure(figsize=(16,10))
for acq_func in acquisition_functions:
print("Acquisition function ",acq_func)
res = my_gpo.evaluate_acquisition_function(x_pred, acquisition_function=acq_func)
if len(res)==len(x_pred):
res = res - np.min(res)
res = res/np.max(res)
plt.plot(x_pred,res, label = acq_func, linewidth = 2)
else: print("Some acquisition function return a scalar score for the entirety of points. Here: ", acq_func)
plt.legend()
plt.show()
Acquisition function variance
Acquisition function relative information entropy
Some acquisition function return a scalar score for the entirety of points. Here: relative information entropy
Acquisition function relative information entropy set
Acquisition function ucb
Acquisition function lcb
Acquisition function maximum
Acquisition function minimum
Acquisition function gradient
Acquisition function expected improvement
Acquisition function probability of improvement
Acquisition function target probability
Acquisition function total correlation
Some acquisition function return a scalar score for the entirety of points. Here: total correlation
ask()ing for Optimal Evaluations#
with several optimization methods and acquisition functions
#let's test the asks:
bounds = np.array([[0.0,1.0]])
for acq_func in acquisition_functions:
for method in ["global","local","hgdl"]:
print("Acquisition function ", acq_func," and method ",method)
new_suggestion = my_gpo.ask(bounds, acquisition_function=acq_func,
method=method, max_iter = 2, dask_client=client)
print("led to new suggestion: \n", new_suggestion)
print("")
Acquisition function variance and method global
led to new suggestion:
{'x': array([[0.99857729]]), 'f_a(x)': array([0.18439853]), 'opt_obj': None}
Acquisition function variance and method local
led to new suggestion:
{'x': array([[0.17045543]]), 'f_a(x)': array([0.0987701]), 'opt_obj': None}
Acquisition function variance and method hgdl
led to new suggestion:
{'x': array([[1.]]), 'f_a(x)': array([0.18890567]), 'opt_obj': <hgdl.hgdl.HGDL object at 0x7f327c6602d0>}
Acquisition function relative information entropy and method global
led to new suggestion:
{'x': array([[0.0015928]]), 'f_a(x)': array([-32.45496285]), 'opt_obj': None}
Acquisition function relative information entropy and method local
led to new suggestion:
{'x': array([[1.]]), 'f_a(x)': array([-138.3052145]), 'opt_obj': None}
Acquisition function relative information entropy and method hgdl
led to new suggestion:
{'x': array([[0.]]), 'f_a(x)': array([-31.19240075]), 'opt_obj': <hgdl.hgdl.HGDL object at 0x7f327d567310>}
Acquisition function relative information entropy set and method global
led to new suggestion:
{'x': array([[0.00045886]]), 'f_a(x)': array([-31.55481133]), 'opt_obj': None}
Acquisition function relative information entropy set and method local
led to new suggestion:
{'x': array([[0.]]), 'f_a(x)': array([-31.19240075]), 'opt_obj': None}
Acquisition function relative information entropy set and method hgdl
/home/marcus/Coding/gpCAM/gpcam/gp_optimizer_base.py:528: UserWarning: I set vectorized=False for total corr. or rel. inf. entropy.
warnings.warn("I set vectorized=False for total corr. or rel. inf. entropy.")
led to new suggestion:
{'x': array([[0.]]), 'f_a(x)': array([-31.19240075]), 'opt_obj': <hgdl.hgdl.HGDL object at 0x7f325e629010>}
Acquisition function ucb and method global
led to new suggestion:
{'x': array([[0.01172727]]), 'f_a(x)': array([1.89992718]), 'opt_obj': None}
Acquisition function ucb and method local
led to new suggestion:
{'x': array([[0.]]), 'f_a(x)': array([1.99938938]), 'opt_obj': None}
Acquisition function ucb and method hgdl
led to new suggestion:
{'x': array([[0.]]), 'f_a(x)': array([1.99938938]), 'opt_obj': <hgdl.hgdl.HGDL object at 0x7f325e6e3910>}
Acquisition function lcb and method global
led to new suggestion:
{'x': array([[0.99424508]]), 'f_a(x)': array([2.39366679]), 'opt_obj': None}
Acquisition function lcb and method local
led to new suggestion:
{'x': array([[1.]]), 'f_a(x)': array([2.42600288]), 'opt_obj': None}
Acquisition function lcb and method hgdl
led to new suggestion:
{'x': array([[1.]]), 'f_a(x)': array([2.42600288]), 'opt_obj': <hgdl.hgdl.HGDL object at 0x7f325e56a190>}
Acquisition function maximum and method global
led to new suggestion:
{'x': array([[0.00125045]]), 'f_a(x)': array([1.43323997]), 'opt_obj': None}
Acquisition function maximum and method local
led to new suggestion:
{'x': array([[0.57817127]]), 'f_a(x)': array([1.07452761]), 'opt_obj': None}
Acquisition function maximum and method hgdl
led to new suggestion:
{'x': array([[0.]]), 'f_a(x)': array([1.43634098]), 'opt_obj': <hgdl.hgdl.HGDL object at 0x7f3308620090>}
Acquisition function minimum and method global
led to new suggestion:
{'x': array([[0.9251833]]), 'f_a(x)': array([2.0131075]), 'opt_obj': None}
Acquisition function minimum and method local
led to new suggestion:
{'x': array([[0.89100372]]), 'f_a(x)': array([1.84875613]), 'opt_obj': None}
Acquisition function minimum and method hgdl
led to new suggestion:
{'x': array([[0.29293917]]), 'f_a(x)': array([0.0439668]), 'opt_obj': <hgdl.hgdl.HGDL object at 0x7f325e483350>}
Acquisition function gradient and method global
led to new suggestion:
{'x': array([[0.80323276]]), 'f_a(x)': array([1.42968872]), 'opt_obj': None}
Acquisition function gradient and method local
led to new suggestion:
{'x': array([[0.85976807]]), 'f_a(x)': array([1.21707289]), 'opt_obj': None}
Acquisition function gradient and method hgdl
led to new suggestion:
{'x': array([[0.80182216]]), 'f_a(x)': array([1.43003972]), 'opt_obj': <hgdl.hgdl.HGDL object at 0x7f325e723cd0>}
Acquisition function expected improvement and method global
led to new suggestion:
{'x': array([[0.00400583]]), 'f_a(x)': array([0.07859944]), 'opt_obj': None}
Acquisition function expected improvement and method local
led to new suggestion:
{'x': array([[0.69696532]]), 'f_a(x)': array([0.03527807]), 'opt_obj': None}
Acquisition function expected improvement and method hgdl
led to new suggestion:
{'x': array([[0.]]), 'f_a(x)': array([0.08752918]), 'opt_obj': <hgdl.hgdl.HGDL object at 0x7f325e52e0d0>}
Acquisition function probability of improvement and method global
led to new suggestion:
{'x': array([[0.00326151]]), 'f_a(x)': array([0.5350753]), 'opt_obj': None}
Acquisition function probability of improvement and method local
led to new suggestion:
{'x': array([[0.77550789]]), 'f_a(x)': array([1.07779943e-76]), 'opt_obj': None}
Acquisition function probability of improvement and method hgdl
led to new suggestion:
{'x': array([[0.]]), 'f_a(x)': array([0.55104161]), 'opt_obj': <hgdl.hgdl.HGDL object at 0x7f325e1d6e90>}
Acquisition function target probability and method global
led to new suggestion:
{'x': array([[0.00299599]]), 'f_a(x)': array([0.34633048]), 'opt_obj': None}
Acquisition function target probability and method local
led to new suggestion:
{'x': array([[0.29110071]]), 'f_a(x)': array([0.]), 'opt_obj': None}
Acquisition function target probability and method hgdl
led to new suggestion:
{'x': array([[0.57053603]]), 'f_a(x)': array([9.87056945e-05]), 'opt_obj': <hgdl.hgdl.HGDL object at 0x7f325e125a10>}
Acquisition function total correlation and method global
led to new suggestion:
{'x': array([[0.50357293]]), 'f_a(x)': array([-3.24201436]), 'opt_obj': None}
Acquisition function total correlation and method local
led to new suggestion:
{'x': array([[1.]]), 'f_a(x)': array([-3.8723385]), 'opt_obj': None}
Acquisition function total correlation and method hgdl
led to new suggestion:
{'x': array([[0.50326358]]), 'f_a(x)': array([-3.24194903]), 'opt_obj': <hgdl.hgdl.HGDL object at 0x7f325e2c7c90>}
#here we can test other options of the ask() command
bounds = np.array([[0.0,1.0]])
new_suggestion = my_gpo.ask(bounds, acquisition_function="total_correlation", method="global",
max_iter=10, n = 5, info = True)
my_gpo.ask(bounds, n = 5, acquisition_function="variance", vectorized=True, method = 'global')
my_gpo.ask(bounds, n = 1, acquisition_function="relative information entropy", vectorized=True, method = 'global')
my_gpo.ask(bounds, n = 2, acquisition_function="expected improvement", vectorized=True, method = 'global')
my_gpo.ask(bounds, n = 1, acquisition_function="variance", vectorized=True, method = 'global')
my_gpo.ask(bounds, n = 3, acquisition_function="variance", vectorized=True, method = 'hgdl', dask_client=client)
print(new_suggestion)
differential_evolution step 1: f(x)= 21.87759314936121
differential_evolution step 2: f(x)= 21.12037920781099
differential_evolution step 3: f(x)= 21.12037920781099
differential_evolution step 4: f(x)= 21.12037920781099
/home/marcus/Coding/gpCAM/gpcam/gp_optimizer_base.py:524: UserWarning: You specified n>1 and method != 'hgdl' in ask(). The acquisition function has therefore been changed to 'total correlation'.
warnings.warn("You specified n>1 and method != 'hgdl' in ask(). The acquisition function "
differential_evolution step 5: f(x)= 20.439267912810713
differential_evolution step 6: f(x)= 20.439267912810713
differential_evolution step 7: f(x)= 20.328735289846882
differential_evolution step 8: f(x)= 20.328735289846882
differential_evolution step 9: f(x)= 20.328735289846882
differential_evolution step 10: f(x)= 20.328735289846882
{'x': array([[0.80066319],
[0.79108331],
[0.49353202],
[0.53110291],
[0.72713549]]), 'f_a(x)': array([-20.32873529]), 'opt_obj': None}
#we can evaluate the acqisiiton function on batches of candidates in parallel:
candidates = np.random.uniform(low = bounds[:,0], high=bounds[:,1], size = (30,1))
candidate_list = [entry for entry in candidates]
#ask sequentially
print("suggestions=", my_gpo.ask(candidate_list, n = 30, acquisition_function="variance", vectorized=False)["x"][0])
#ask in parallel on DASK workers, but sequentially on each worker:
print("suggestions=", my_gpo.ask(candidate_list, n = 30, acquisition_function="variance", vectorized=False, batch_size = 10, dask_client=client)["x"][0])
#ask in parallel on DASK workers, and vectorized (if possible) on each worker:
print("suggestions=", my_gpo.ask(candidate_list, n = 30, acquisition_function="variance", vectorized=True, batch_size = 10, dask_client=client)["x"][0])
#ask vectorized (if possible):
print("suggestions=", my_gpo.ask(candidate_list, n = 30, acquisition_function="variance", vectorized=True)["x"][0])
print("They should be the same!")
suggestions= [0.5118965]
suggestions= [0.5118965]
suggestions= [0.5118965]
suggestions= [0.5118965]
They should be the same!
bounds = np.array([[0.0,1.0]])
#You can even start an ask() search asynchronously and check back later what was found
new_suggestion = my_gpo.ask(bounds, acquisition_function=acquisition_functions[0], method="hgdlAsync", dask_client=client)
time.sleep(10)
print(new_suggestion)
new_suggestion["opt_obj"].kill_client()
{'x': array([[0.]]), 'f_a(x)': array([-0.]), 'opt_obj': <hgdl.hgdl.HGDL object at 0x7f325dc6e210>}
[{'x': array([0.]),
'f(x)': np.float64(-0.18768280111824148),
'classifier': 'degenerate',
'Hessian eigvals': array([0.]),
'df/dx': array([2.30888748]),
'|df/dx|': np.float64(2.3088874782639657),
'radius': np.float64(0.0)},
{'x': array([0.5110164]),
'f(x)': np.float64(-0.1407138191164292),
'classifier': 'zero curvature',
'Hessian eigvals': array([0.]),
'df/dx': array([-0.00015813]),
'|df/dx|': np.float64(0.0001581332287337034),
'radius': np.float64(0.0)},
{'x': array([0.20313894]),
'f(x)': np.float64(-0.11094946537844927),
'classifier': 'minimum',
'Hessian eigvals': array([29.08706609]),
'df/dx': array([-5.10327891e-07]),
'|df/dx|': np.float64(5.10327891056761e-07),
'radius': np.float64(0.034379541647070695)},
{'x': array([0.86068642]),
'f(x)': np.float64(-0.11049344113842001),
'classifier': 'minimum',
'Hessian eigvals': array([8.85820584]),
'df/dx': array([-5.48616708e-07]),
'|df/dx|': np.float64(5.486167076185211e-07),
'radius': np.float64(0.11288967750000069)},
{'x': array([0.3656675]),
'f(x)': np.float64(-0.09296362356046356),
'classifier': 'zero curvature',
'Hessian eigvals': array([0.]),
'df/dx': array([1.159145e-05]),
'|df/dx|': np.float64(1.159145002205264e-05),
'radius': np.float64(0.0)},
{'x': array([0.36566666]),
'f(x)': np.float64(-0.09296362355930513),
'classifier': 'minimum',
'Hessian eigvals': array([14.17341244]),
'df/dx': array([-1.98244199e-07]),
'|df/dx|': np.float64(1.9824419883462951e-07),
'radius': np.float64(0.07055463911548977)}]